『はじめて学ぶバイナリ解析』本の非公式実行環境を作った
『はじめて学ぶバイナリ解析』実行環境(非公式)
『はじめて学ぶバイナリ解析』本1の非公式実行環境をDockerで作成し、MITライセンスで公開しました。公式では実行環境をVirtualBoxで提供していますが、資材が1.7GBと軽いのが特徴です。
作った経緯など
公式で提供されたVirtualboxの環境ががM1 Macでうまく動かせなかったので、最初は「M1 Macで課題が動かせる環境」を作ろうと思いました。 ところが、構築を進めていくうちに、デバッガや可視化ツールの多くはM1 Macのチップセットに対応していないことや、Intel系とArm系では命令セットの体系が大きく異なるので演習課題を同じように進められないことがわかり、M1 Mac用の環境構築は諦めました。公開した資材はUbuntu 22.04(x86_64)で動作確認済みです。
本を読んだ・課題をやった感想
本書はCTF(Capture The Flag)の初歩的な課題として取り上げられるStack Overflow攻撃の仕組みを理解することがゴールになっていて、前半ではその仕組みを理解するためのアセンブリ言語やスタック、レジスタ、デバッガの使い方などについて説明しています。
基本的に前提知識を必要とせず、書いてあることを読めば理解できるので非常に読みやすかったです。
課題は大学の時にやった情報処理演習みたいで楽しく進めることができました。課題自体は理解しやすかったですが、環境構築で結構な時間をロスしました。今回公開した環境を使うことで課題に集中できるようになれば幸いです。
Kaggle Notebook実行環境と仮想環境の運用について
概要
今回作ったKaggle Notebook実行環境の構成の紹介と、機械学習の実験環境におけるpython仮想環境の運用方法について書く。
経緯
これまでAnacondaでpytorch, tensorflowなどと主要なフレームワークごとに仮想環境を作り、複数のプロジェクトで使い回す運用をしていた。pytorchやpandasなどの基本的なパッケージが入っていればよく、また実験環境なのでパッケージの厳密なバージョンは特に気にしてなかったので特に大きな問題もなく運用できていた。
ところが、最近KaggleのOttoコンペをやるようになって、RAPIDSやらMarlinやら、数百Mのデータテーブルを効率的に捌くためのフレームワークが必要になってきて、仮想環境が何個も生えるようになった。
このくらいの数(4-5個)なら特に管理はしていけるだろうが、Anacondaの管理の問題点1も見えてきたので、そろそろちゃんと管理したいなと思っていた。
本腰を入れて対応しようと思ったきっかけは、Kaggle Notebookを手元で動かそうとして、環境の違いのせいで、実行できるようするための無駄なインフラ作業(機械学習と関係のない作業)が発生していたことである。
幸いKaggleは公式のdocker imageを公開しているし、dockerの構築方法についての情報もかなり出回っているので、Kaggle Notebookの実行環境のクローンを作りつつ、Anacondaの仮想環境管理からdockerによるイミュータブルなインフラ運用に移行することにした。
Kaggle Notebook実行環境のクローンを作る
dockerと公式のdocker imageのインストールについては公式のドキュメントや、個人のブログ記事などがすでに多くあるのでここでは書かない。
ここでは実際に作った構成の要件と運用イメージを述べるにとどめる。
要件
- Notebookの修正を最小限にする
- notebookの変更内容やnotebookのアウトプット(モデルの重みなど)はホスト環境に残したい
- データセットもホスト環境にダウロードしたものをコンテナからアクセスできるようにする
- コンテナ起動中に変更された構成はいつでも初期化できるようにする
2, 3はvolumeの設定でできるし、4はdockerコンテナを削除すればよい。 1はフォルダのパスをKaggleに合わせればほぼ問題ない。
コンテナ内のフォルダ構成
- /kaggle/working: ノートブックを保管する場所
- /kaggle/input: データセットを保管する場所
- /kaggle/jupyter_lab_config.py: jupyter lab の設定ファイル
運用イメージ
あるNotebookをこの環境で動かしたい場合、
- 依存しているKaggleのデータセットをKaggle APIで取得し、ホストマシンの
/kaggle/inputと同期されたディレクトリ内に展開する - Kaggleのnotebookページからダウンロードしたipynb形式のファイルをjupyter labの管理画面からアップロードする。アップロードしたノートブックはワークディレクトリ
/kaggle/workingに入り、ホストマシンと同期される。 - notebookを手動でステップ実行する。inputのパスが元のnotebookと異なる場合は適宜書き換える
- 実行結果は
/kaggle/workingと同期したホストマシン上のディレクトリに保持される - 実行完了後、コンテナを削除して状態を初期化する
ソースコード
今回作成したdockerの起動設定用の資材をGitHub2で公開する。セットアップ方法などはこちらに詳しく記載したので、参照実装として有効活用していただければと思う。
Anacondaを脱却してコンテナ+pipによる管理へ
今回の課題はKaggle Notebookのクローン環境を作ることだったわけだが、コンテナによる運用はKaggleに限らず、パッケージの厳密な依存性管理を必要としない任意の機械学習プロジェクト3に適用してメリットがあると考えている。以下にその理由を説明する。
各ツールの担当範囲
以下ではAnacondaとコンテナ+pipの運用を比較したいのだが、それぞれがどのレイヤを担当しているかを混同すると言ってることが理解しづらいと思うので、ツールごとの担当レイヤを表1に整理しておく。違いは、簡単にいうと、Anacondaはベースとなる環境とプロジェクトごとの差分に特に切り分けがないため全てpython仮想環境で担当しているが、コンテナ+pipの運用ではベース環境をdocker、プロジェクトごとの差分をpipで行うという点である4。
表1. 各ツールの担当範囲
| 担当範囲 \ 運用パターン | Anaconda | コンテナ+pip |
|---|---|---|
| ベースとなる環境の定義 | python仮想環境 | dockerコンテナ |
| プロジェクトごとの差分の定義 | python仮想環境 | pip |
Anaconda運用のパターンと課題
Anacondaでは仮想環境でベースとなる環境もプロジェクトごとの差分も定義しなくてはならない。したがって、以下のどちらかのパターンで運用することになる。
- プロジェクトごとに独立した仮想環境を使う
- 複数のプロジェクトで共通の仮想環境を流用する
プロジェクトごとに独立した仮想環境を作る運用の課題は、リソースの重複が大きいことである。たとえばGPUに対応したpytorchは数Gバイトのディスク容量を消費するが、これがプロジェクトごとに重複して管理される。また、インストールしたパッケージの一覧があるわけではないので、何をインストールしたのかが分かりにくいという点がある。
逆に、複数のプロジェクトで共通の仮想環境を流用した場合(前述のpytorch共通環境のような運用イメージ)、あるプロジェクトで新しいパッケージをインストールしたくなった場合に共通環境にインストールすることになるが、インストールによって他のプロジェクトの構成にも影響が及ぶ可能性がある。たとえば、パッケージAをインストールすることで他のプロジェクトで使われているパッケージBのバージョンが代わり、他のプロジェクトが動かなくなる可能性がある。
Anacondaと比較したコンテナ+pip運用のメリット
コンテナ運用のメリットは以下である。
- リソースの重複が最小限
- 共通環境が変化しにくい
- 万が一環境を破壊してもすぐに元に戻せる
まず、地味なところではリソースの重複が少ない点が挙げられる。Anacondaは仮想環境とプロジェクトごとの差分を切り分ける手段がないので、プロジェクトごとに仮想環境を作る必要があるが、コンテナであればベースとなる環境をコンテナで管理し、プロジェクトごとの差分をpipで管理する、という切り分けができる。これによって、pytorchのように数GB消費するパッケージを何個もインストールする必要がなく、ディスク消費とインストールの時間を節約することができる。
また、Anacondaで「pytorch共通環境」のようなベース環境を用意した場合、pytorchプロジェクトでは同じ仮想環境を流用するので新しいパッケージをインストールするたびに共通環境が変化していく。コンテナ運用ならプロジェクトごとの差分はDockerfileに記述したpipでインストールするので、共通部分となるbase imageを変える必要がなく、デグレなど共通環境特有の心配がない。
さらに、たとえば、Anacondaの仮想環境にpipで誤ってパッケージをインストールしてしまった場合を想像して見てほしい。pipで手動でインストールした変更はAnacondaの管理外なので、これらをアンインストールするには、依存関係も含めて何が変わったのかを一つ一つ確認して切り戻す必要がある。戻せなければ仮想環境を一から作り直す必要がある。これに比べてコンテナは一度きりの使い捨てなので、コンテナを削除すれば起動中にインストールした変更を元に戻すことができる。
Anacondaと比較したコンテナ+pip運用のデメリット
注:元々「pipは依存性の管理ができない」という前提で書いていたが、これはpip 20.2以前の話で、20.3以降のバージョンでは依存関係リゾルバーが実装されている5。したがって元の記述は削除した。
まとめ
- Kaggle Notebookのクローン環境の要件と資材構成について共有した
- 仮想環境の管理方法についてAnacondaと比較したコンテナ運用のメリットについて主張した
補足: 記事の変更点について
この記事では最初「コンテナ+pipenvライクなツール」による運用管理のメリットについて書いていたが、そもそもpipenvやその類似ツールはプロジェクトごとにpython仮想環境を作成するため、「共通基盤の設定を流用してプロジェクトごとの差分のみを定義する」といった運用はできない。
このため、コンテナによる運用のパターンを「コンテナ+pip」と改め、適用範囲を「任意の機械学習プロジェクト」から「厳密なパッケージの依存性管理を必要としない任意の機械学習プロジェクト」と改めた。
また、「Anacondaと比較したコンテナ+pip運用のデメリット」の節を追加した。
自宅のマシンに外部からSSH接続する各種パターンについて
概要
自宅に構築したPC/サーバに、外部のネットワークからSSH接続する場合の構築パターンについてまとめる。
前提条件
- 自宅の回線は通信事業者が提供する一般家庭向きの回線を想定。したがってIPアドレスは可変。
- 自宅マシンは基本的にCLIで操作する(GUIは使わない)。したがって通信量はさほど多くない想定。
- 一般的なIaaS/PaaSに構築する場合と比べてセキュリティリスクが同程度かそれ以下であること(例:パスワードでログインしない、ポートはSSHのみ解放)。
- CLIを作業する時にレスポンスが十分速くて作業にストレスを感じないこと(レイテンシが100ms以下)。
- 運用費用は1,000円/月以下であること。
実現方法の候補
- グローバルIP固定
- 通信事業者が提供している固定IPアドレスサービスを契約し、自宅PCをインターネットに公開する。
- Dynamic DNS
- Dynamic DNSサービスを契約し、FQDNとIPアドレスの紐付けをDDNSによって管理してもらう。
- 踏み台サーバ + リバースSSHトンネリング
- 踏み台サーバ + VPN
- VPNサービス
- 4と同様な構成が一般消費者向けサービスとして提供されている。例)GlocalVPN
- sishサーバ
それぞれの実現方法の特徴
| 実現方法 | メリット | デメリット | 運用費用 | |
|---|---|---|---|---|
| 1 | グローバルIP固定 | 最も基本的な構成。 | 回線業者及びプロバイダがサービス提供している場合のみ利用可能。 | 880円/月〜*1 |
| 2 | Dynamic DNS | 無料のDDNSサービスを利用すれば運用費用がかからない。 | IPが変わる前後で接続できない時間が生じる(数分〜数十分)。DDNSサービスがダウンしている場合は接続できない。*2 | 無料〜 |
| 3 | リバースSSHトンネリング | 自宅ルータのポート解放設定が不要。踏み台サーバ上に認証情報をおかなくて良い。 | 何らかの原因でSSHセッションが切断された場合は接続できなくなる。 | 643円/月〜*3 |
| 4 | VPN | - | - | 643円/月〜 |
| 5 | sish | - | - | 643円/月〜 |
※メリットデメリットがよくわからなかったものは空欄にしています。
最終的に選択した構成
著者の契約している回線プロバイダは固定IPのサービスを提供していなかったので1以外で検討した。 2はセキュリティ上の懸念が払拭できなかったため、検討から除外した。 また、5は仕組みがよく分かっていないので判断ができず、検討から除外した。 セキュリティの観点からは3と4はほぼ同等と考えられるが、3の方が設定内容が少なく、構成もシンプルと考えたためこの構成を選択した。
*2:特に無料のDDNSサービスの場合は、IPとFQDNの紐付けが汚されるといったセキュリティ上の懸念があるのではと筆者は考えているが、脆弱性について明確に言及されたソースは見つけられなかった。
*3:ConoHa, さくらのVPSで最小の構成で1ヶ月レンタルする場合の費用を基準とした(ConoHa(512MB): 682 円/月, さくらのVPS(512MB): 643円/月)。
data poisoningがモデルに与える影響について
はじめに
9日前に終了したKaggleコンペ「AI Village Capture the Flag @ DEFCON1」にて、data poisoning という攻撃手法を題材にした課題があった。 data poisoning2というのは、攻撃者が訓練サンプルに異常な(=poisoned)訓練データを混ぜ、攻撃者にとって都合が良い学習結果となるようにモデルの学習プロセスに介入する攻撃手法である。
この課題3ではLeViTというtransformerベースの画像認識モデルにおいて、毒入りサンプルを混入させて学習した重みが与えられ、元の毒入りサンプルが何であったかを厳密に特定するというものだった。
学習に用いたサンプルは、図1に示したような3x3の9つの領域からなる正方形の各セルの中央にそれぞれ円を配置した図形からなる。配色は全部で9色使われていて、それぞれの9つの正方形、および円は9つの色を全て使って塗られる。また、同じセル内にある正方形と円は異なる色で塗らなければならない。 単純計算だとこのような制約を満たす配色の方法は9! x 9! = 約1,300億通りあるが、これらの膨大なパターンの中からたった1つの毒入りサンプルを特定することが求められた(実際にはコンペ終了後のヒントでさらにパターンは絞られた)。

この課題自体はサンプルが毒入りかどうかを示す評価を定義して見込みの薄いサンプルを刈り込みながらヒューリスティックに探索する方法によって解かれた4のだが、EDAをしている中で、多クラス分類の判別境界を図示する方法を試したので備忘録としてメモしておく。
多クラス分類における判別境界
判別境界とは、特徴空間において異なるクラスを連続する領域に分割するとき、それらの領域の境界にあたる多次元曲面をさす。線形分類の場合はこの領域は超平面となる(図2)。

そもそもなぜ先に示した課題において判別境界を図示する必要があるかというと、毒入りサンプルによってモデルの判別境界が大きく変動するからだ(図3)。図3左は2次元の特徴空間上に各クラスの分布を示したものだ。赤い丸で示した点にクラス0の偽のラベルを付加した毒入りサンプルを全サンプルの25%追加してある。健常なサンプルと毒入りサンプルによって線形判別モデルを学習した結果を図3右に示す。この図からわかる通り、クラス0と3の判別境界(黒線)は大きく毒入りサンプル側に近づき、これらのクラスの識別能力に影響を与えている。

このように、大量の毒入りサンプルで学習したモデルはクラスの判別境界が大幅に変動する。しかしながら、この変動の方向はある程度規則的だと想定されるので、変動後の判別境界のずれ方から、毒入りサンプルの特徴空間上での位置を予測可能ではないかと考えた。
毒入りサンプルによる特徴ベクトルの分布への影響
課題で与えられたモデルは深層学習モデルなので、最終層の線形判別層だけでなく、特徴ベクトル(=最終層の直前の特徴ベクトル)にも影響が及ぶと考えられる。
図3では特徴ベクトルの分布の様子を図示した(コンペの課題におけるEDA5の結果をそのまま掲載する)。なお、解法が既に共有されているので、毒入りサンプルの位置を左上、中央上にそれぞれ三角印で示している。この課題では、クラス7の特徴を持つサンプルをクラス8のラベルを付けて訓練されている。図3中央上では毒入りサンプルの特徴空間上での位置は、クラス7と8の中間あたりに来ている(次元削減方法がPCAなので距離の比は保持されることに注意)。これはおそらく、本来ならクラス7の中心付近に来るべき特徴を、毒入りサンプルに付加した偽のラベル(=クラス8)によってクラス8の特徴として学習したため、特徴ベクトルがクラス8側に移動したためと考えられる。
なお、他の健常なサンプルについてはほぼクラスタにまとまっており、毒入りサンプルの影響はほとんど受けていないように見える。図3下行に示したt-SNEの結果でもはっきりとした塊にまとまっている。

以上のように、毒入りサンプルの混入によって特徴ベクトル自体にも影響を受けることが確かめられた(もちろん解法なしにこのような事前知識は得られないが、ここでは毒入りサンプルの影響を考察することが目的なので問題ない)。
毒入りサンプルによる判別境界への影響
続いて最終層の線形層における判別境界を図4に示す。少し見づらいが、この図ではバツ印でモデルの予測したラベルを図示し、三角印で真のラベルを図示した。つまり、同じ色で異なる印の点が近い場合はモデルの予測性能が高いことを示し、逆に離れている場合はモデルの予測性能が低いことを示す。この図では大部分が正解のラベルの分布と予測のラベルの分布が離れているので、モデルの予測はほとんどランダムに近いであろうことが見て取れる。残念ながら、この図からは規則的な傾向のようなものは見られず、この結果が毒入りサンプルによってもたらされたのかどうかを判定することさえ難しい。

せっかくなので、毒入りサンプルの影響をほぼ受けていないと考えられる蒸留ヘッドの判別境界も図5に示す(LeViTはViTに似たアーキテクチャを採用していて、教師ありサンプルで学習するヘッドと、事前学習済みのCNNから知識蒸留によって学習するヘッドの合計2つの線形判別レイヤを持つ)。この図の結果は非常に明快で、全ての2クラスの組み合わせについて判別境界がクラスの概ね中央付近に来ている。この結果は健常なサンプルで学習した分類器の典型的な判別境界を示している。

おまけ: 判別境界の可視化方法について
最後に、この投稿で用いた可視化方法について説明をしておく。
線形多クラス分類モデルの判別境界
結論を先に書くと、バイアスなしの線形モデルでは「線形層の重み行列をクラスごとにベクトルと見做した場合、判別境界は原点を通り、2つのクラスの重みベクトルどうしをつなぐ直線と直交する直線である」。バイアスありの場合も直線の開始点が原点から移動するだけで、基本的にはこの性質が保たれる。
図2, 3の右側に星印で示した点が「線形層の重みベクトル」である。図からわかるように、判別境界はこれらの任意の2つの星印を繋いだ直線と直行している。
詳細な導出過程及び結果の式は注のリンク6に示した。
多次元特徴空間上の判別境界を2次元に可視化する方法について
2次元特徴空間上の分布を図示するのは直接的に可能だが、3次元以上の場合は判別境界が超平面となるため、可視化に工夫が必要である。
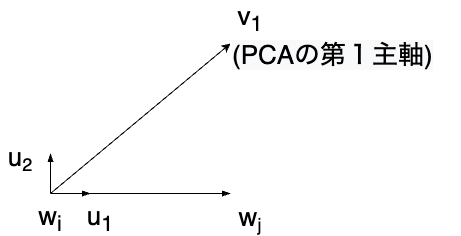
ここでは「判別境界(超平面)に直行する基底ベクトル」を2つ選んでその平面に射影した。 なお、このような基底ベクトルの選び方は無限に存在するが、ここでは以下の方法を採用した。
- 2つの重みベクトルの差のベクトルを正規化したベクトルを第1軸とする
- PCAの第1主軸を計算し、このベクトルと第1軸を含む平面上で、第1軸に垂直な単位ベクトルを第2軸とする
具体的な計算方法は以下に示す(図6)。
: 可視化の第一軸
: 可視化の第一軸
: クラスiの重みベクトル
: クラスjの重みベクトル
: PCAの第一主軸
詳細は注5に示したEDAのコードを参照して欲しい。
終わりに
この投稿ではAI Villageコンペの課題の例を使って、毒入りデータが特徴ベクトルや判別境界に与える影響について考察した。また、多次元特徴空間上における線形モデルの判別境界を2次元上に図示する方法について紹介した。