data poisoningがモデルに与える影響について
はじめに
9日前に終了したKaggleコンペ「AI Village Capture the Flag @ DEFCON1」にて、data poisoning という攻撃手法を題材にした課題があった。 data poisoning2というのは、攻撃者が訓練サンプルに異常な(=poisoned)訓練データを混ぜ、攻撃者にとって都合が良い学習結果となるようにモデルの学習プロセスに介入する攻撃手法である。
この課題3ではLeViTというtransformerベースの画像認識モデルにおいて、毒入りサンプルを混入させて学習した重みが与えられ、元の毒入りサンプルが何であったかを厳密に特定するというものだった。
学習に用いたサンプルは、図1に示したような3x3の9つの領域からなる正方形の各セルの中央にそれぞれ円を配置した図形からなる。配色は全部で9色使われていて、それぞれの9つの正方形、および円は9つの色を全て使って塗られる。また、同じセル内にある正方形と円は異なる色で塗らなければならない。 単純計算だとこのような制約を満たす配色の方法は9! x 9! = 約1,300億通りあるが、これらの膨大なパターンの中からたった1つの毒入りサンプルを特定することが求められた(実際にはコンペ終了後のヒントでさらにパターンは絞られた)。

この課題自体はサンプルが毒入りかどうかを示す評価を定義して見込みの薄いサンプルを刈り込みながらヒューリスティックに探索する方法によって解かれた4のだが、EDAをしている中で、多クラス分類の判別境界を図示する方法を試したので備忘録としてメモしておく。
多クラス分類における判別境界
判別境界とは、特徴空間において異なるクラスを連続する領域に分割するとき、それらの領域の境界にあたる多次元曲面をさす。線形分類の場合はこの領域は超平面となる(図2)。

そもそもなぜ先に示した課題において判別境界を図示する必要があるかというと、毒入りサンプルによってモデルの判別境界が大きく変動するからだ(図3)。図3左は2次元の特徴空間上に各クラスの分布を示したものだ。赤い丸で示した点にクラス0の偽のラベルを付加した毒入りサンプルを全サンプルの25%追加してある。健常なサンプルと毒入りサンプルによって線形判別モデルを学習した結果を図3右に示す。この図からわかる通り、クラス0と3の判別境界(黒線)は大きく毒入りサンプル側に近づき、これらのクラスの識別能力に影響を与えている。

このように、大量の毒入りサンプルで学習したモデルはクラスの判別境界が大幅に変動する。しかしながら、この変動の方向はある程度規則的だと想定されるので、変動後の判別境界のずれ方から、毒入りサンプルの特徴空間上での位置を予測可能ではないかと考えた。
毒入りサンプルによる特徴ベクトルの分布への影響
課題で与えられたモデルは深層学習モデルなので、最終層の線形判別層だけでなく、特徴ベクトル(=最終層の直前の特徴ベクトル)にも影響が及ぶと考えられる。
図3では特徴ベクトルの分布の様子を図示した(コンペの課題におけるEDA5の結果をそのまま掲載する)。なお、解法が既に共有されているので、毒入りサンプルの位置を左上、中央上にそれぞれ三角印で示している。この課題では、クラス7の特徴を持つサンプルをクラス8のラベルを付けて訓練されている。図3中央上では毒入りサンプルの特徴空間上での位置は、クラス7と8の中間あたりに来ている(次元削減方法がPCAなので距離の比は保持されることに注意)。これはおそらく、本来ならクラス7の中心付近に来るべき特徴を、毒入りサンプルに付加した偽のラベル(=クラス8)によってクラス8の特徴として学習したため、特徴ベクトルがクラス8側に移動したためと考えられる。
なお、他の健常なサンプルについてはほぼクラスタにまとまっており、毒入りサンプルの影響はほとんど受けていないように見える。図3下行に示したt-SNEの結果でもはっきりとした塊にまとまっている。

以上のように、毒入りサンプルの混入によって特徴ベクトル自体にも影響を受けることが確かめられた(もちろん解法なしにこのような事前知識は得られないが、ここでは毒入りサンプルの影響を考察することが目的なので問題ない)。
毒入りサンプルによる判別境界への影響
続いて最終層の線形層における判別境界を図4に示す。少し見づらいが、この図ではバツ印でモデルの予測したラベルを図示し、三角印で真のラベルを図示した。つまり、同じ色で異なる印の点が近い場合はモデルの予測性能が高いことを示し、逆に離れている場合はモデルの予測性能が低いことを示す。この図では大部分が正解のラベルの分布と予測のラベルの分布が離れているので、モデルの予測はほとんどランダムに近いであろうことが見て取れる。残念ながら、この図からは規則的な傾向のようなものは見られず、この結果が毒入りサンプルによってもたらされたのかどうかを判定することさえ難しい。

せっかくなので、毒入りサンプルの影響をほぼ受けていないと考えられる蒸留ヘッドの判別境界も図5に示す(LeViTはViTに似たアーキテクチャを採用していて、教師ありサンプルで学習するヘッドと、事前学習済みのCNNから知識蒸留によって学習するヘッドの合計2つの線形判別レイヤを持つ)。この図の結果は非常に明快で、全ての2クラスの組み合わせについて判別境界がクラスの概ね中央付近に来ている。この結果は健常なサンプルで学習した分類器の典型的な判別境界を示している。

おまけ: 判別境界の可視化方法について
最後に、この投稿で用いた可視化方法について説明をしておく。
線形多クラス分類モデルの判別境界
結論を先に書くと、バイアスなしの線形モデルでは「線形層の重み行列をクラスごとにベクトルと見做した場合、判別境界は原点を通り、2つのクラスの重みベクトルどうしをつなぐ直線と直交する直線である」。バイアスありの場合も直線の開始点が原点から移動するだけで、基本的にはこの性質が保たれる。
図2, 3の右側に星印で示した点が「線形層の重みベクトル」である。図からわかるように、判別境界はこれらの任意の2つの星印を繋いだ直線と直行している。
詳細な導出過程及び結果の式は注のリンク6に示した。
多次元特徴空間上の判別境界を2次元に可視化する方法について
2次元特徴空間上の分布を図示するのは直接的に可能だが、3次元以上の場合は判別境界が超平面となるため、可視化に工夫が必要である。
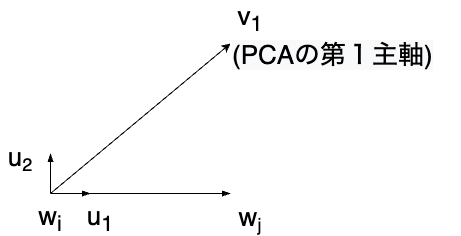
ここでは「判別境界(超平面)に直行する基底ベクトル」を2つ選んでその平面に射影した。 なお、このような基底ベクトルの選び方は無限に存在するが、ここでは以下の方法を採用した。
- 2つの重みベクトルの差のベクトルを正規化したベクトルを第1軸とする
- PCAの第1主軸を計算し、このベクトルと第1軸を含む平面上で、第1軸に垂直な単位ベクトルを第2軸とする
具体的な計算方法は以下に示す(図6)。
: 可視化の第一軸
: 可視化の第一軸
: クラスiの重みベクトル
: クラスjの重みベクトル
: PCAの第一主軸
詳細は注5に示したEDAのコードを参照して欲しい。
終わりに
この投稿ではAI Villageコンペの課題の例を使って、毒入りデータが特徴ベクトルや判別境界に与える影響について考察した。また、多次元特徴空間上における線形モデルの判別境界を2次元上に図示する方法について紹介した。